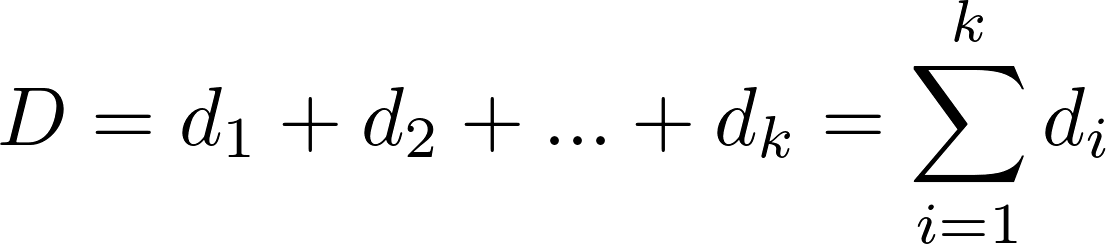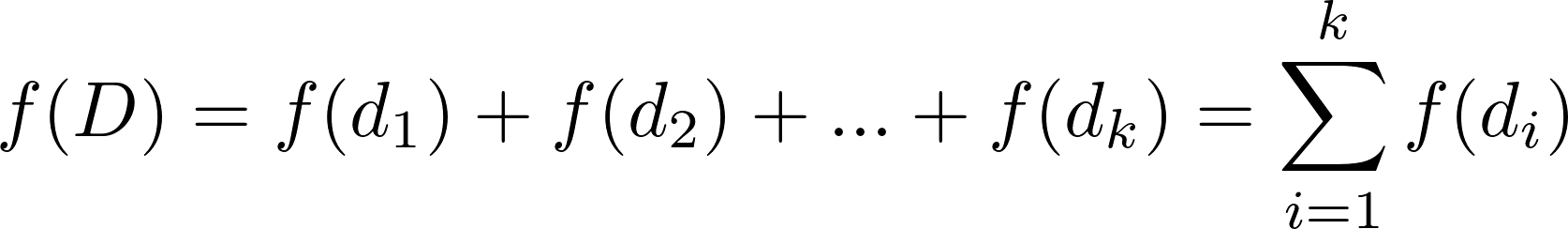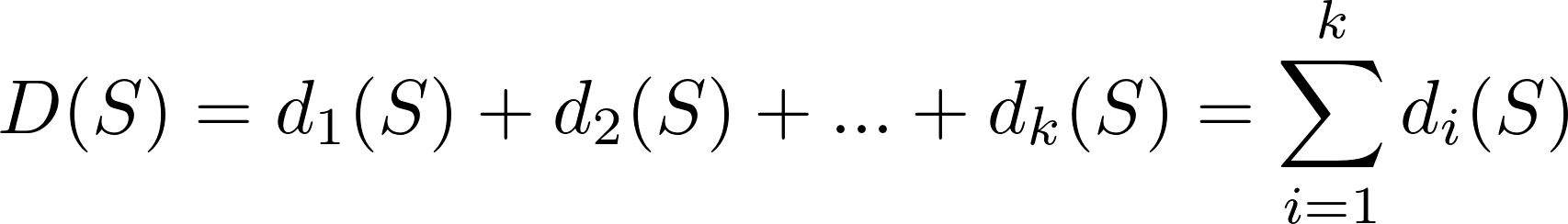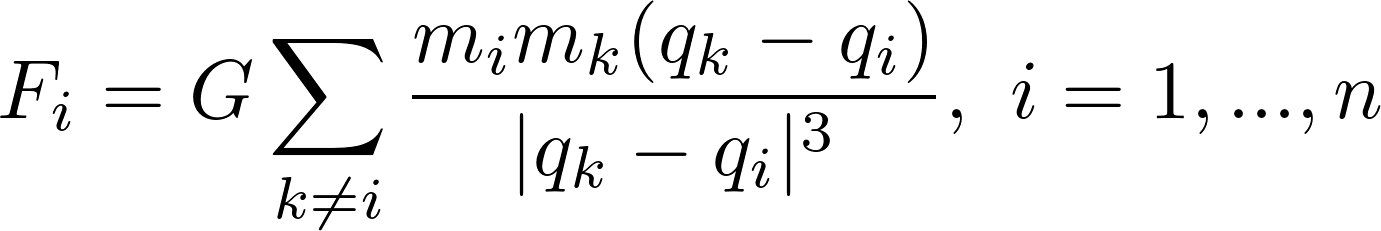| Rápidas y robustas, de las CPU´s a las GPU´s: Computación paralela y sus aplicaciones en problemas de datos paralelos utilizando arquitecturas GPU |
|
|
La computación paralela se ha convertido en un tema importante en el campo de la informática y ha demostrado ser crítica cuando se investigan soluciones de alto rendimiento.
Hubo un periodo de la historia en que los procesadores trabajaban de manera secuencial. En aquella época un procesador más poderoso significaba básicamente un aumento en las frecuencias de reloj y una mayor densidad de transistores, lo que en conjunto se traducía en mayor poder de cómputo. La ley de Moore dice que la densidad de transistores se duplica aproximadamente cada dos años. Hoy en día esta ley se sigue cumpliendo, sin embargo ya no es posible aumentar el rendimiento de los programas de manera automática como lo fue en algún momento de la historia, dado que las frecuencias de reloj alcanzaron su límite. A raíz de este problema nace lo que llamamos la computación paralela, la cual se ha transformado en una herramienta esencial para la ciencia y en una fuerte rama de investigación para las ciencias de la computación.
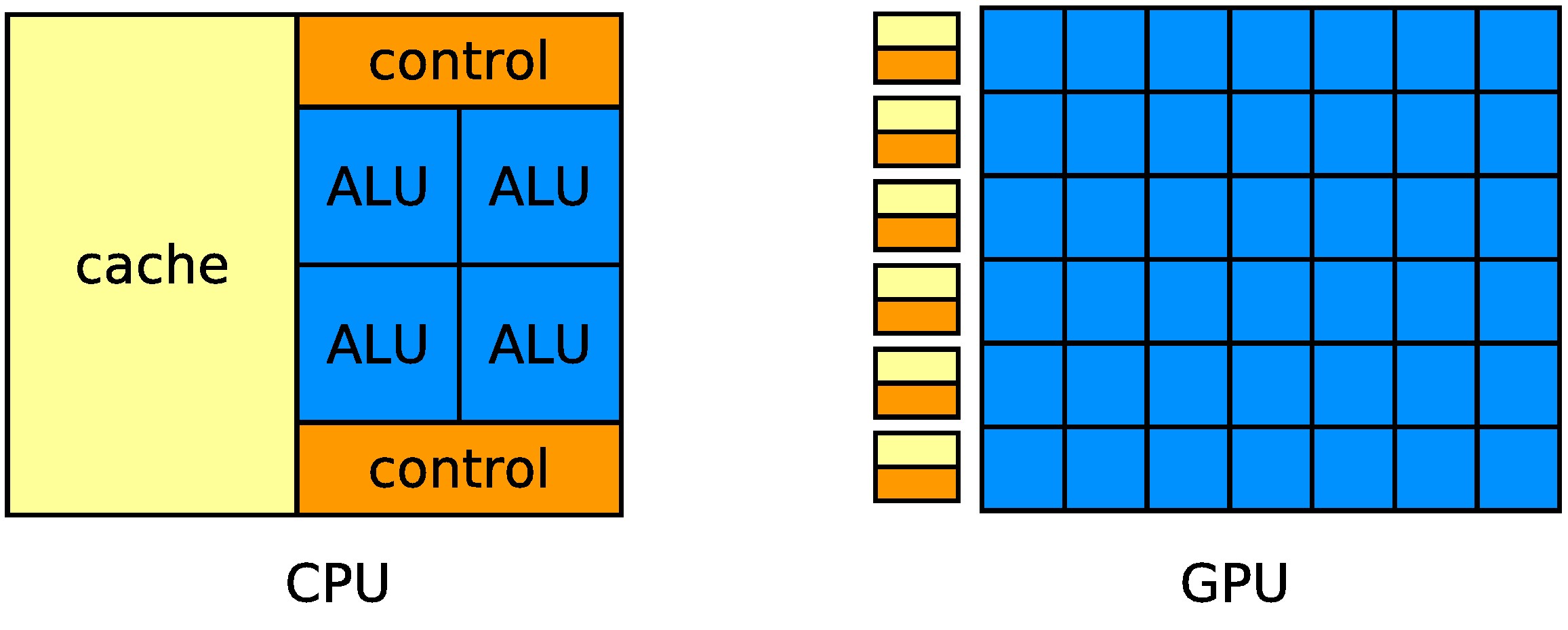
La evolución de arquitecturas computacionales (multi-core y many-core) hacia un mayor número de núcleos puede comprobar que el paralelismo es el método de elección para la aceleración de un algoritmo. Para algunos problemas computacionales, los algoritmos basados en la CPU no son suficientemente rápidos para dar una solución en un plazo razonable de tiempo. A veces, estos problemas pueden llegar a ser grandes, hasta el punto que ni los algoritmos basados en la CPU multi-núcleo (multi-core) son suficientemente rápidos. Problemas como éstos se pueden encontrar en la ciencia y la tecnología, las ciencias naturales (física, biología, química), tecnologías de la información (IT), los sistemas de información geoespacial (GIS), problemas de mecánica estructural e incluso problemas de matemática abstracta y ciencias de la computación (CS). En el artículo de Cristóbal Navarro, del Laboratorio de Física del CECs, se señala que utilizando la computación paralela, muchas de las soluciones a estos problemas pueden ser ahora computadas (calculadas) en un período de tiempo razonable. La arquitectura de la GPU es prácticamente el opuesto a la CPU (ver Figura 1), puesto que sacrifica flexibilidad para obtener más rendimiento informático.
Figura 1. Diferencia entra la arquitectura CPU (izquierda) y GPU (derecha). La computación paralela es el acto de la solución de un problema de tamaño n dividiendo su zona en k ? 2 (with k ? N) partes y resolverlos con procesadores físicos P, de forma simultánea. Ser capaz de identificar el tipo de problema es esencial en la formulación de un algoritmo paralelo. Que P D sea un problema con la zona (dominio) D. Si P D puede ser paralelizado, entonces, D se puede descomponer en k sub-problemas:
P D es un problema de datos paralelos si D se compone de datos y resolver el problema requiere la aplicación de una función del núcleo f (…) para todo el dominio:
P D es un problema de tarea paralela si D se compone de funciones y la solución del problema requiere la aplicación de cada función a una corriente de datos común:
El problema de n-cuerpo es un problema de interacción donde n cuerpos o partículas son afectados por la gravedad de otra n - 1 cuerpo en un espacio k-dimensional (por lo general K = 2 o k = 3). Lo interesante en este problema es que para un sistema de sólo tres partículas no se ha encontrado ninguna solución analítica todavía. Por esta razón, el n-cuerpo es uno de los problemas de datos paralelos emblemáticos hallados en la física computacional, y el objetivo es simular el sistema a través del tiempo en vez de resolverlo. El problema de n- cuerpo establece que para cada partícula su fuerza está dada por sus interacciones con las otras partículas:
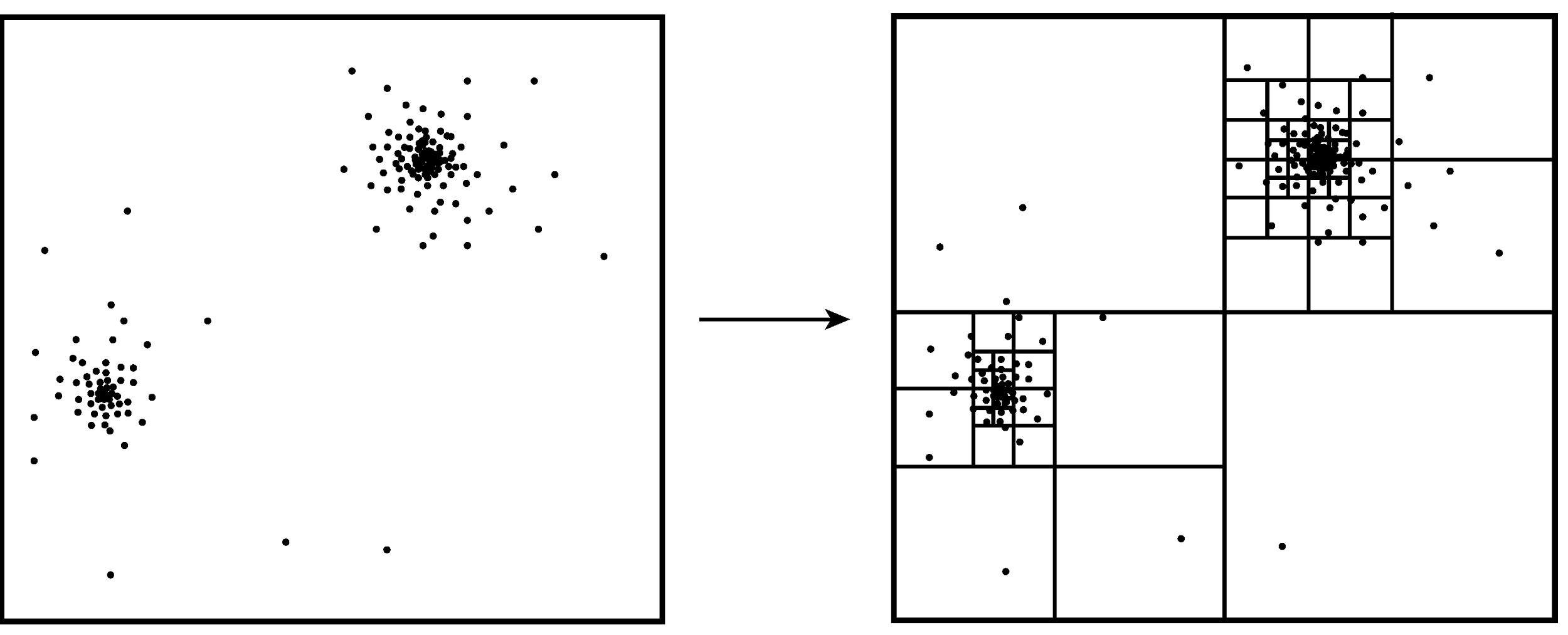
Una simulación clásica requiere un algoritmo O(n ^2 ) ya que es el tipo de problema all-with-all. Una solución GPU puede procesar partículas en paralelo, lo que resulta en un algoritmo O( n^2 / p ) donde p es la cantidad de procesadores. La investigación sobre simulaciones de n-cuerpos ha encontrado que los métodos más rápidos existen si sacrifican alguna precisión numérica. El argumento se basa en el hecho de que las contribuciones de los términos de suma disminuyen cuadráticamente con la distancia entre dos cuerpos. Como resultado, los cuerpos muy lejanos de un cierto cuerpo no hacen ninguna contribución significativa a su fuerza final, mientras que los cuerpos cercanos de ese mismo cuerpo hacen la mayor parte de la contribución a su fuerza final. Esta importancia de las contribuciones es la clave para el diseño de un algoritmo más rápido de n-cuerpo. El algoritmo de código arbóreo (dendroideo) Barnes-Hut es una solución conocida de partición espacial que logra O(nlog_k(n) ) tiempo promedio por paso de tiempo. Se utiliza un quad-tree para k = 2 o equivalentemente un oct-tree para k = 3. El árbol se utiliza para guardar las medidas de grupos de puntos lejanos del punto de referencia (Figura 2).
Figura 2. Un quad-tree aplicado sobre dos grupos de puntos.
Cuando la simulación se ejecuta en GPUs, ella puede hacer muchas partículas utilizar el árbol en paralelo. Esta mejora en el tiempo de cálculo permite estudiar sistemas mucho más grandes en el orden de millones de partículas. Muchos otros problemas físicos pueden ser tratados en paralelo utilizando GPUs. El único requisito inicial para el problema consiste en ofrecer lo suficiente de datos de paralelismo. Sin embargo, el rendimiento final dependerá también de los patrones de acceso de memoria y la comunicación entre elementos de datos. Patrones de acceso que mantienen localidad de elementos de datos incurren en alto rendimiento, mientras que los patrones de acceso dispersos presentan un desafío adicional de la reordenación de los datos de una manera diferente, o utilizar las caches manuales de la GPU.
--- Referencia: C. A. Navarro et al. (2014) A Survey on Parallel Computing and its Applications in Data-Parallel Problems Using GPU Architectures. Commun. Comput. Phys. doi: 10.4208/cicp.110113.010813a
|